TDLR The speaker discusses their experience migrating from MySQL to TiDB, highlighting the challenges they faced with performance and query optimization, as well as the need for thorough testing and preparation before deploying TiDB.

Thank you everybody for attending this talk today. I’ll be talking about a case study of how our product team moved on to Thai DB from MySQL. The interesting bit about this is we are actually a product team, we’re not an info team. I think there’s many info teams, sort of hanging around in this conference, so we’ll talk about sort of where we came from, why we’re going there and all of that.
So the goals of this talk are threefold: to share our experience and our learning by explaining why we chose Thai DB, sort of how we chose Thai DB, the context around it, as well as showing some of the work needed to run Thai DB in production. Finally, we’ll wrap up by presenting some problems we encountered and how we handle those problems.
Are there questions at this point about the goals of this talk? Yes, I’m breaking the normal mold by asking for questions sort of in the middle of the talk, so please feel free to ask as you think of them. Oftentimes people forget their questions by the end.
Okay, continuing onward.

So, quick outline: I’m going to talk a little bit about our team because our team impacts how the decisions were made. I’ll also introduce our products so you can know what we’re actually doing and what our customers are seeing. Then, I’ll explain why we’re looking for a new database and how we decided on a solution. After that, I’ll give a quick overview of the areas of work, although it will be a subset due to time constraints. Following that, Christina will lead us off with a deep dive into some of the unexpected problems we ran into. Finally, I’ll conclude. Okay, let’s start with the team.

Our team is actually much larger than this as a product team, but these were the key people who worked on the project of migrating our database. It’s important to note that we all come from infrastructure backgrounds, which played a significant role in the decisions we made. Jacqueline and myself conducted research on RAM, cloud, and Arachne, which are distributed low latency key value Stores. Christina has experience in performance reliability at Facebook, while Lay has worked at Intel and New Relic, specializing in low-level systems for observability.
Now, let me provide some information about our product to give you an understanding of the data we handle.
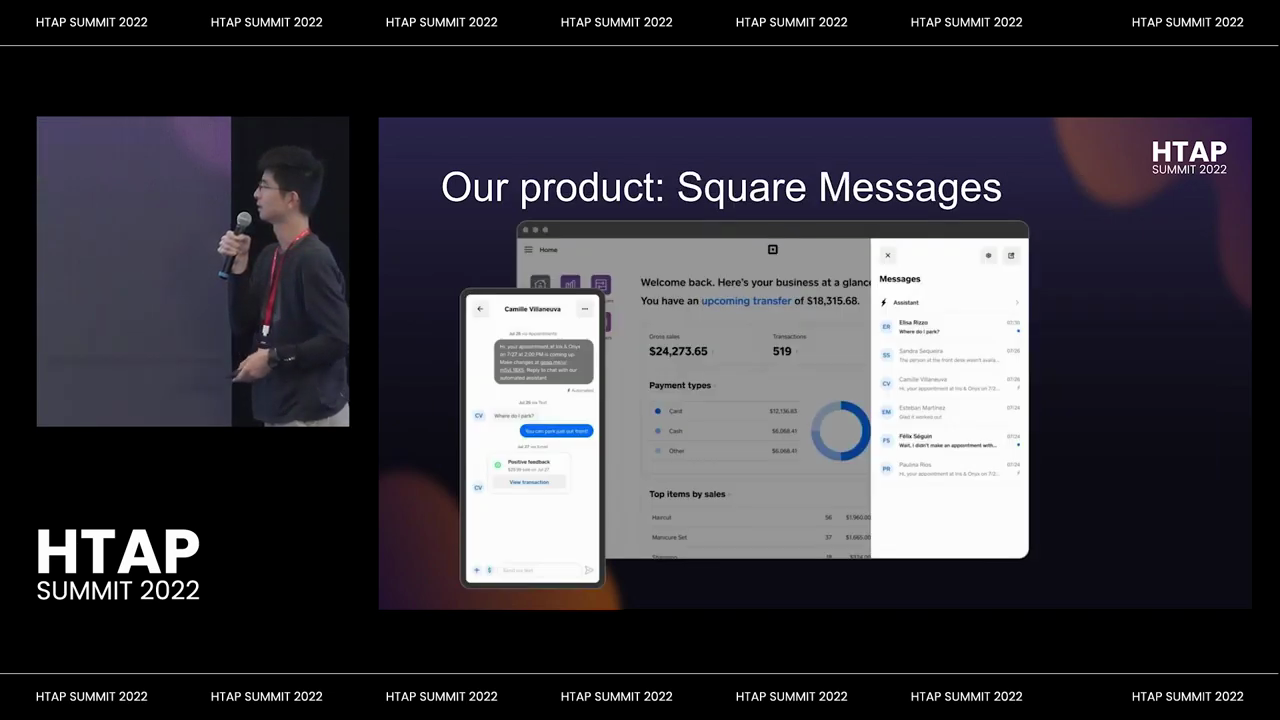
Square Messages is a product that unifies buyer or seller communication for Square sellers. Unification means that sellers have a single interface in the Square Dashboard app and every Square point of sale, where they can have a unified conversation with each buyer. For Square buyers, they can see messages through email, SMS, and Facebook Messenger (with the possibility of integrating more platforms in the future). The left side of the screen shows the buyer experience, while the right side shows the seller experience. Additionally, Square Services can use an internal API to send messages through Square Messages, which allows the messages to be visible in the Square Messages UI and the replies to be visible to sellers. If Square Services do not integrate with Square Messages and send SMS directly, the replies are not visible. The product handles millions of messages per month, making it a moderate volume workload. Due to the various services sending messages through Square Messages, the workload is write-heavy compared to other workloads. This is why they are looking for a new database.

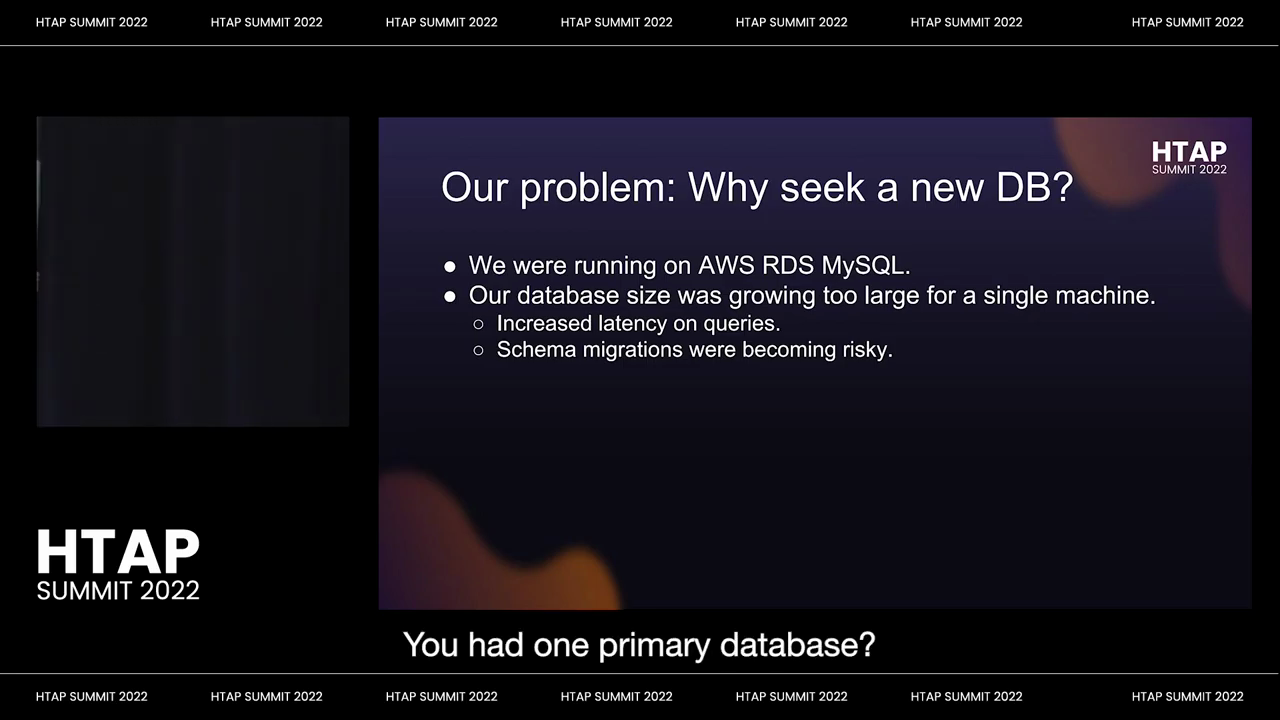
We were originally running on AWS RDS, MySQL, which is also relevant for a future discussion. But the high-level bit is that our database was simply growing too large for a single machine, so we’re getting close to two terabytes. Around the time of migration, we’re starting to see increased latency on a larger and larger frequency of queries, and schema migrations were starting to become risky. Moreover, there were migrations that we were just afraid to run because we knew they would bring us down for a long time, for example, column deletions being a very common one. So you have a whole bunch of columns that are sort of marked deprecated in your schema but are still sitting around your database. We’re very happy to be able to get rid of those soon.
Any questions at this point about our product or the problem we’re trying to solve? I hope you’re not all falling asleep.
I have one question. You had one primary database, or was there? You have Assist another database for high availability in another location, or how did you handle that?
So when we were first starting Square messages. Right, the product itself wasn’t yet established, so we had a single read-write replica and then we had a read-only replica, effectively for quasi-analytics, but also as a failover. Yeah, but I think it was a different availability Zone, but the same region. We’ve always been in US West too.
Other questions or comments at this point? Okay, I’m going to go ahead and move on. Thank you for the thumbs up.

Okay, so how are we deciding what to go with? We started out by brainstorming a whole bunch of requirements for what we might like in our new database and then we threw them all out the window.
The primary reason for throwing them out the window is because the single most important criteria for being able to run this solution within block is that somebody else at block had already run it. The reason for this is because we have unique compliance and networking constraints within block, as we are a fintech company and we also operate on pii.
So, if you just pick a random solution off of the internets- let’s say cockroach- and then you said you want to run it at block, you got to go through legal review, you got to go through security review, you have to go through compliance review. That was a lot of pain that we as a product team did not want to go through.
Instead, we sort of looked at the existing options at Square that somebody had already gotten approved through these processes.
So the different options we looked at were manually sharded. MySQL is still the blessed path at Block. It is very sad, but this is still the case and it’s the path that most teams have chosen to take. It’s the path that our online data stores infrastructure team supports. But of course, it increases complexity in your application, it slows down feature development, and you have to deal with all sorts of pain. You do schema migrations tool despite the existing tooling.
Then we have Dynamo. Dynamo is very, very popular for teams with very simple data models. If you have one or two tables, if you’re okay with a limited number of global secondary indexes, Dynamo is an excellent solution. In our case, we had very large relational data models for our transcripts and utterances, as well as our metadata and various AI analytics. Dynamo was not a good choice for us.
And then there was Aurora, which was kind of interesting because if we were read-heavy, we’d actually be okay, but we actually are a fairly write-heavy workload, as I mentioned earlier. So there was a lack of write scalability, which was actually a pretty big problem for us. Moreover, yes, it’s a little bit more scalable than MySQL, but we didn’t want a solution that would require us to find a new solution a year later. We wanted to come to a solution that would allow us to last for many years.
And then that brings us to the new SQL databases. We have tested TIDB. But TIDB was actually used by Cash within Block for a while and it was considered operationally difficult. What does that actually mean? I actually looked at the architecture and found that it was indeed not very easy to deploy, as well as being inconvenient for application developers because it required cross-share transactions to be considered differently from single on-char transactions.
And then we had TIDB, which is being recommended by Cash TV, but never used that square.
So just a bit of background here: within block, square and cache are two different business units, but they also have two separate pieces of infrastructure for historical reasons. So things that are used by one do not necessarily work for the other.
So actually, in terms of how we made our choice, the team was actually leaning towards manual sharding, but and so like because this again was the Blessed path, right.

Even though Thai DB satisfied many, but not all, of the properties we had originally brainstormed, there were concerns about setup and operational cost. We talked to various teams and looked at other documentation from different product teams. We found that many teams considered using High DB but ultimately decided against it because they would have to manage and set it up themselves, as well as maintain and update it. This was a new experience for the Square side of the business, so there were concerns about that.
As a result, we started leaning towards manually sharding. I was worried about how messy our code would become if we went with manual sharding. Unable to sleep, I decided to look at the architecture of Thai DB. Drawing from my expertise in distributed systems from my PhD, I concluded that Thai DB was a reasonable option in terms of maintainability and scalability. I knew it would require work, but it was doable.
I took a week to hack together a running cluster in production to demonstrate that we could run High DB. It didn’t have SSL or the production readiness we would expect, but we got it running. I convinced the team to change direction, so we dropped the manual sharding and switched over to idb.
Okay, I’m gonna move on. By the way, this makes the talk much more fun for me and for you. Thank you for all the questions. Are there questions or comments before we move on? Yeah, happy to chat after too. Does that address your question?
Moreover, they did look at multi-cluster Solutions, but they decided that those Solutions were too complex and too expensive because they required running a lot more eks clusters than they wanted to run.
Sure, so at a high level bit, you want to be able to have an upper bound on both how much data you lose in the case of a regional failure as well as an upper bound on how long it takes to recover, and based on the existing mechanism, namely Thai CDC, they were not able to achieve the the 10- I think it was a 10 minute time to recover that they wanted.
What is missing in idb? What do you mean by Disaster Recovery? Other questions or comments: can you elaborate?
We were okay with not having that, at least for the time being, but like that was, that was a blocker for cache DB. So, like as an infrastructure team for cache DB to support this, they they require that you have cross-regional Disaster Recovery as a relatively newer product within Square. The main reason is disaster recovery.
Yes, so I’ve already shared this with other folks in pin cap. Can you concern that? Why did they ended up not using it? So what?
Yeah, one more question: um, so you you said that cashdb a DD lot of probably legal and some reviews to get it like through right. They became low velocity teams, so like that was another point for us. They used to be high velocity teams.
Every single team at Square I’ve seen do manual sharding. There’s another interesting data point which was while we were going around saying we’re going to do manual sharding, our- I guess our- GM, Willem, looked at our Dock and said please don’t do manual sharding. They took about really six months to manually Shard the first time and then, like every two years, they have to reshard and when they do feature development they always have to think about, like, how well manual charting works or doesn’t work.
Well, I’ve talked to a few teams. That’s one data point and in terms of how much, how much like pain they go through. So a lot of the teams that manually Shard are actually much larger than ours. That’s a good question. Your problems is that: is there a big enough pain point from the other teams? Well, I stopped.
And you mentioned you don’t really like the manual Charter idea because code will be very dirty. So other product teams including, for example, invoices at Square are doing manual sharding and they basically maintain that logic inside their application. That’s correct. Do they do manual charging for other products. Do they?
Yes, so the manual Charter- there’s other teams. So we don’t know yet, but we’re not actively doing stuff with it Beyond sort of cleaning up the tech that we use for the migration itself. I mean the cluster is currently running and only one person is actively still doing work on it, but we’ve only run for two weeks in production. So, like the, we’re sorry. We still are managing the cluster. Questions or comments about this part of the journey.
The next part of the talk will be a little bit boring but, I hope, informative. Areas of expected work.
So first of all is the obvious one. This one like: if you’re an application team, regardless of whether you have infrastructure support or not, you have to do this part. So application updates for compatibility.
So one of the biggest pain points for us in terms of updates was that we were relying on the monotonic increasing Auto incrementing IDs throughout many parts of our application, and the fact that Thai DB’s sort of Auto incrementing IDs jump around a little bit because of the caching of IDs meant that we had to replace all the places we’re resorting by IDs with sorting by timestamps, and you think this is not very hard.
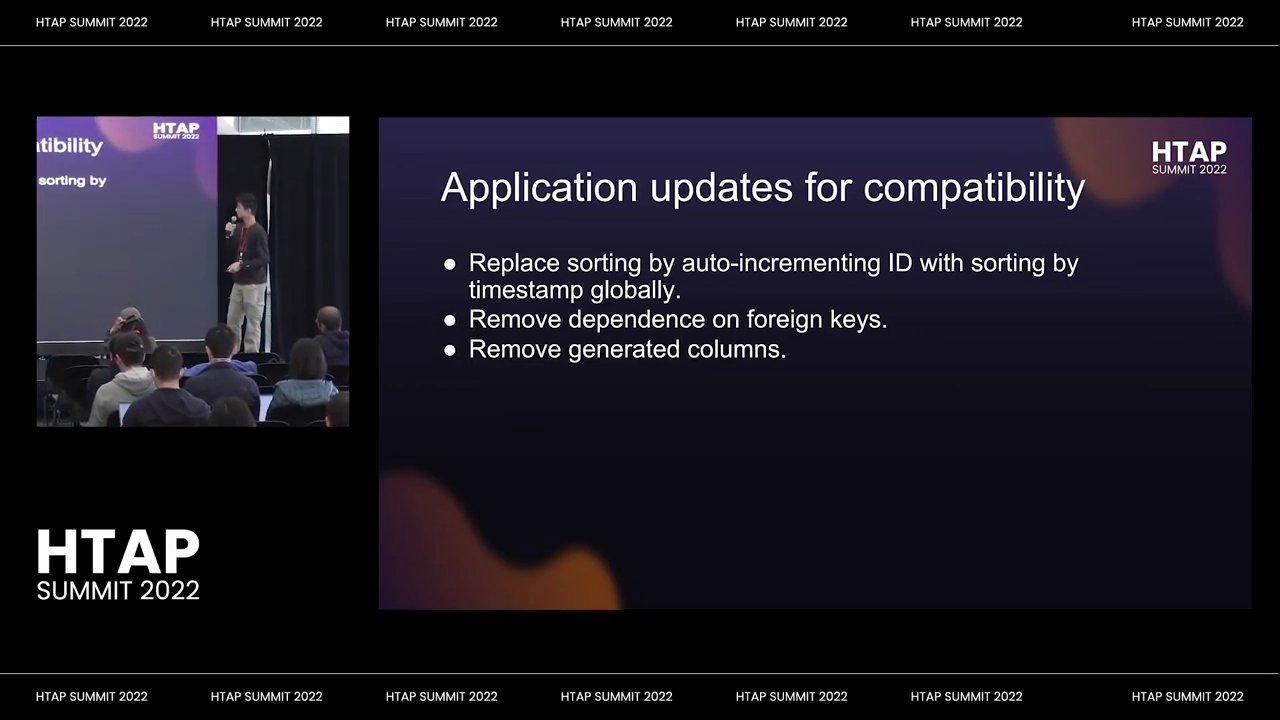
But we had a lot of places and they interacted in very subtle ways. So we end up denormalizing part of our database schema for this reason. So that was one bit of work. The other was removing dependencies on foreign keys. So what do I mean by dependencies on foreign keys? What I mean is we’re using on delete Cascade for a variety of use cases, including gdpr and CCPA compliance. So we have to get rid of that dependence and then eventually re-implement that logic in Java.
The last one, which Christina will get more into, is we have to remove the use of generated columns because we learned a little bit too late that generated columns are an experimental feature in Thai DB.
Questions about application updates for compatibility: we got one there and one there. So, regarding the sodiby, the timestamp globally, how do you ensure the timestamp is, I mean, like there’s accuracy? Right, it’s different than the unique, the auto increment the ID. So how do we ensure that you can always sort by the timestamp? We’re relying on the timestamp Oracle in the PD component of Thai DB to have globally, globally, monopolically increasing timestamps.
Yeah, did something go wrong with the generated columns or did you not even try it? I don’t want to spoil Christina’s part of the talk. We’ll get there soon. We’ll get there soon. Other questions at this point? Okay, I’m gonna go ahead.
So the next phase of sort of validation: when you go to any new database, you have to validate that your system still achieves comparable performance compared to using MySQL. And this is I want to be very clear here. We’re not saying Thai DB has to match MySQL performance.

We’re saying our service when running High DB has to match our service when running MySQL. This is a subtle but important distinction because, like, if the database is not the bottleneck in your system, then you may not actually observe a huge performance degradation when you move to a slower database.
So we did find some of these, as Christina will get into, and then we had to investigate and sort of fix the queries that were slower in Thai DB. And tidy B is great but, like, when you migrate from any system to any other system, I would be extremely surprised if you did not run into at least one of these things.
So, yeah, questions about this. This was multiple weeks of benchmarking and performance experiments.
Okay, moving on. So data migration was also like a bit of a pain point for us. We wanted to design a migration plan for orchestrating service deployments so that we didn’t lose any data consistency and we also didn’t lose any data. There were some limitations in the data migration Tool.

Thank you, Ed, for fixing the SSL issues, or at least asking people to fix the SSL issues. But there was also this issue of migrating from AWS RDS. You cannot take the global read lock because Amazon does not give you permissions to do so. Sorry Amazon people for calling that out. I’m sure there are good reasons for it, but because you cannot take the global read lock, you end up having to do a bit of shenanigans to get what we wanted.
We ended up with a read-only replica on which we pause replication temporarily and then we took a snapshot on that replica and then resumed it and waited for it to catch up. So there’s a bit of an elaborate dance to get this migration working. Fortunately, we weren’t trying to fully automate that whole process because we’re just one product team, we’re not an info team.
Questions about data migration. One question: that process, the cut over time. How much downtime was that? A very good question. We did this literally two weeks ago and this was eight minutes of downtime. We were waiting. We basically stopped all writes. It wasn’t full downtime because we are in read-only mode. I have a backup slide about that if people are curious later. But like, yeah, we were in read-only mode for eight minutes and we queued all service messages, so we didn’t lose any messages. Good question.
Other questions: so do you have any data schema migration you need to do like a store procedures or any other stuff. You need to migrate when you do this. Yeah, so I alluded to this a little bit earlier. But yes, we also had to get rid of anything that required basically running constraints, constraint checking, anything that relied on constraint checking, like foreign key constraint checking. We had to migrate over to Java, so there were some migrations, but they weren’t really large compared to the application changes. We also removed all of our foreign keys because we figured it would be more confusing people see the foreign keys and have them not do anything than to not see the foreign keys and then be confused about why.
So, that was a bit of a debate inside our team when we were first starting this journey. I have a question here: hello, so hi. So how long did it take you overall from when you started looking at Thai DB to the time that you went live two weeks ago? I think it was more than six months for, I guess, roughly two and a half Engineers- because, like I guess, Christina and Jacqueline worked on other projects too while we were doing this, but lay was on it full time. I was running roughly half time. So roughly two and a half Engineers for about six months or so.
Okay, thank you. Yeah, it has occurred to me that this, the space is small enough you could just shout. You don’t actually need micropods. That’s probably true. But when you consider data migration and any project that you’re doing, how do you weigh the scope of data migration versus the efficacy of the project? Like, when does data migration become a problem?
Define the scope of data migration, like are you talking about the effort it takes to do the migration? Yes, ah, okay, so so, if I’m understanding the question correctly, you’re asking, like: how do we decide whether or not this amount of work was worth it? Okay, in in our case, like if you look at the options we had, if we went with manually charted my SQL, we probably have roughly an equal amount of work, and then in a few years we had to recharge again. If you look at sort of Aurora, that’s again, at least from our point of view, a crutch for a short-term solution, and a lot of the other Solutions had not yet been proven inside block. So it wasn’t so much like was this worth the work. It was more like: what choice do we have? Yeah, and it was choosing among different expensive options. Yeah, and I’ll be very free to admit that we we certainly underestimated the cost of this migration when we started, but let our learning, that our sort of underestimation, be your learning. Other questions or comments? Okay, let’s continue. Let’s continue. Do we skip a slide? Okay, the last bit of work.
I know, mate. At the beginning, like in the keynote, Max talked about how it was kind of unfortunate that we still have to show data into Snowflake. But in our case, we do have to shove data in Snowflake, and there is a very good business reason for it.
The business reason is that nobody else is on High DB at Square, so we have to shove our data into Snowflake. This allows us to join our data with everybody else’s data to do with the OLAP workloads.
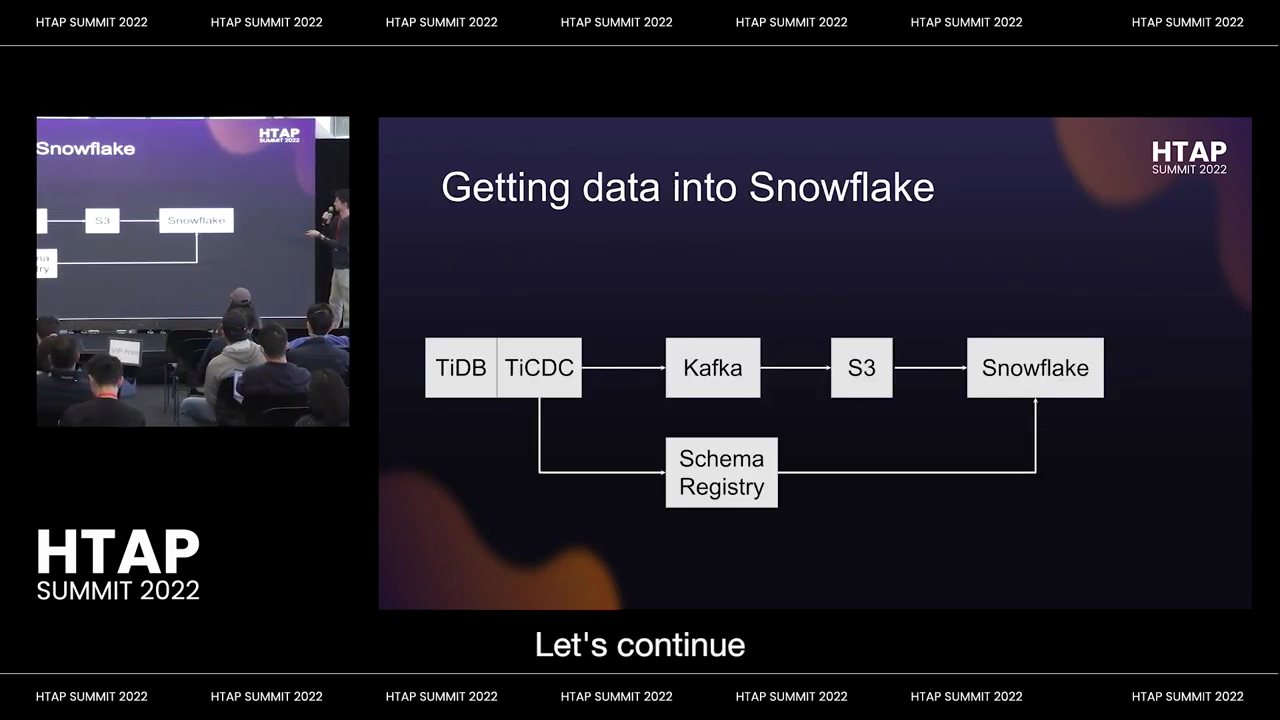
But this, this was a non-trivial amount of work because it turns out that most of this pipeline exists for MySQL at square but not for tidy B at square, and the little differences are enough to cause us to have to re-implement many parts of it. If there’s time, enough time, I may talk more about this later on, but this just identifying a piece of work that, if you have, if you need snowflake or you need something like snowflake for analytics, then you wind up with this particular bit of work.
One question on the diagram. So it looks like all the data from the tables is being dumped into the S3 and from there you’re taking it directly into ingesting it into the snow pipe using snow pipes. I don’t think we’re actually using snow pipe, I think we’re just using normal staging loads. To be clear, I’m not an expert on snowflake, so some of the terminology I might be wrong about.
Thank you. Are there questions at this point?
We got one over there. Yeah, at least I think that’s a question. Maybe he just wants the mic.
Hey, so Thai DB’s oltp plus olap. So have you considered using its olap power? And it isn’t to migrate to snowflake any specific use cases you are looking for?
Yeah, so what I was saying earlier is that the reason we’re migrating to snowflake or writing data to snowflake is because all of the other data at Square lives in Snowflake and we want to do joins against that. So, for example, like names of customers, for example transactions that a particular customer has had, or like appointments data or receipts data or invoices data. All of that lives in Snowflake at square and, like we cannot convince like 10 other product teams to all migrated idb very effectively, considering how much time we spent doing it.
Yeah, okay, I have lost my timekeeper. Sorry to call you out, but I’m gonna continue. Hopefully I’m not running too far over time.
Okay, so now I’m gonna give the stage to Christina to start us on unexpected problems and solutions.
“Hello, I’m Christina. I work with Henry at Square/Block. I’m going to start off with the section on the Steep dive section, where we talk a bit more about the unexpected things that we ran into in our tidy B adventures and our best efforts to solve them or at least address them.
Specifically, I’ll start off this section with a focus on performance and the query level issues that we ran into. Whenever you try to switch over to a new database, even though TiDB claims MySQL compatibility, there’s always the fear of the unknown, especially with regards to performance. Switching over to TiDB could introduce new performance bottlenecks and issues, so no one likes surprises.
To avoid these surprises, before actually switching over in production, we ran best effort performance experiments in our staging environment. Specifically, that looked like running latency tests and load tests against our service level endpoints, not the actual queries, because that was our primary focus, like Henry mentioned earlier.
Based on those results, we ran into some interesting findings. But first, a high-level theme that came up was joins were noticeably slower in TiDB compared to MySQL. Our performance tests also helped us track down no-op joins that had no business existing in our codebase. Removing them did improve throughput by about five percent off the top of my head, but that was like low-hanging fruit.”

I think the key bottleneck for us that was most concerning, considering that we’re right heavy, is rights that involved table joints. So specifically, we saw that for one particular right in our critical path, the throughput was 30 of the equivalent in RDS MySQL, which is not good. But this is like right off the box.
So we proceeded to look closer at the execution plans about what exactly was happening. We noticed two things. One was that a lot of time was spent trying to fight for the lock across these multiple queries, which kind of makes sense given high concurrency. And the second issue, which is a bit more of a mystery that we still need to investigate further, is that the TiKV layer was quite busy for the queries that were happening in the throughput scenario. We were seeing updates happening for more keys than we expected that we did not see for the latency tests. We were still not quite sure where these extra keys are coming from. But the current hypothesis, a very high-level hypothesis, is that this has something to do with the concurrency of writing to the same row at the same time.
But we didn’t want to block this investigation any further. We didn’t want to block a switch over in production any further. So we tabled this to a post switchover in production. And for now, we had our switch over two weeks ago and then we were just resorting to a quick and dirty hack where we just simply break the query into two and avoid the join at all costs.
But now that we’ve had our switch over two weeks ago, we do want to definitely revisit this now that we have the time. Specifically, by trying to come up with a more bare bones, minimal reproducible example and get to the root cause of what exactly is happening in this throughput scenario and, you know, hopefully benefit the TiDB community. Yeah, and then, yeah, this was.
It seemed like a lot of people were interested in generated columns. So here we are finally.
So I guess a bit more context about how we even got to generated columns. As Henry mentioned earlier and for those who still have not maybe caught on, like anti-db, Auto incremented IDs are not monotonically increasing, so we had to replace all sorting instances on that with sorting by timestamps.
One of the initial approaches we took with introducing those timestamps was to use generated columns.

But that worked fine, except when we actually tried to index on the generated columns we saw two sorts of unexpected behavior. First was that the results were just wrong and then the second was also in addition to that: the results were different depending on which columns were being selected in the query. But later on we should have known this earlier.
But later on we realized that generator columns in Thai DB are an experimental feature anyway and we don’t want experimental features in production anyway. So we got rid of. The solution was to replace the generator columns with like explicitly manually added columns and doing baxles.
So far I’ve talked about issues - performance and query related issues that we saw in staging, but now I’m going to talk a bit more about things that happened after the actual switchover in production, which is interesting.
We had our switch over two weeks ago and then about a couple, a couple hours after the switch over, we noticed one particular endpoint - thankfully not a critical functionality - in our product timing out more frequently than usual. I got a slack message from Henry at 9:00 PM being like: “Hey, Christina, this query is timing out more than usual.”

Sure, I can look at it. It’s at 9pm.
I was looking at the execution plans of this particular query and turns out that the Thai KV level was very busy with rpcs for fetching information about columns that were in the where clause that could easily be optimized using an index. Also, this provides more context on this query. This is a query involving joins across three tables. It has always been one of our more problematic queries, but I think we are seeing the latency impact being more exaggerated and noticeable in Tidy B compared to our regular RDS.
So, based on what we found in the execution plans, we decided to try to add a composite index that covers all the columns in the where clause. That took a while, but eventually, it did help reduce timeouts. Thankfully, that was the only big performance issue we saw post switchover in production two weeks ago. So overall, not bad in my opinion.
But I think the key takeaway from this overall, not just this particular instance, but the overall journey and adventures in Tidy B, is that Tidy B claims to be MySQL compliant, but that doesn’t quite hold true. You can’t take that at face value, especially with performance. It was definitely crucial to pay due diligence, invest time to investigate, and de-risk performance implications when switching over to Tidy B.
But yeah, I’ll hand it over to Henry for the remaining talking.

One quick question: did any queries run faster than expected when you migrated over?
There were, but we were very happy. We didn’t quite take the time to investigate why exactly. But some of the queries were surprisingly faster. But we were like, Yay, but let’s just move on and focus on the bottlenecks. But yeah, we didn’t focus on the bottlenecks photo, there were perf ones for sure.
Yeah, so say this is the question, you will get the attention. One more question: yeah, we are. I’m reminded that we’re running a little bit out of time, but you should go ahead with your question.
Sorry question for her when. When she said missing indexes, what do you mean? Where are they missing by Design or missing a mistake, or yeah?
So this was an oversight on our part. So I think for our, the speculation is that for certain classes of queries, MySQL either does table scans faster or uses partial indexes more effectively. So in this case, we had to add an explicit index that matched exactly what the join query and that sort of fixed it. But we hadn’t realized this because we didn’t see this problem in staging. So they were missing, like not intentionally but inadvertently.
Christina, do you want to have something?
Yeah, I think one of the key reasons we didn’t see this in staging, we didn’t catch this in staging, was because, like, fundamentally, we do have different state data and staging and production and I think the patterns and production were more likely to make this issue visible, especially since it’s like a three table, join the. The particular pattern of you know, like having that particular pattern and relationship of the data and in staging was, yeah, it’s hard to predict, yeah, anyways.
Okay, since we’re running low on time, I’ll go very quickly over the last two slides before we go on to more Open Session. So quick learning about eks cuddle. It turns out that when you try to set up an eks cluster using eks cuddle in an environment with no outbound internet connection, it doesn’t like you very much. So we could have gone with terraform or any of the sort of other more heavyweight infrastructure infrastructure as code techniques, but we decided to just hack this with Ed because we’re a product team and we didn’t want to spend that much time playing with eks. So we ended up literally just writing bash scripts that edited the environment while ek’s cuttle was running.

That was kind of just mostly for fun, and talk more about it offline every time. The last bit was kind of interesting for those of you who want to get stuck in the snowflake: turns out that the S3 connector, which is a confluent cloud product, is not capable of using a connect proxy with credentials, so like we actually contact their customer support. And they said, no, we don’t support this. So I said, fine, I’ll shove your traffic through a socat and force it with credentials through our Cloud proxy, which is just a squid proxy. So with that, I will conclude.
So we chose tidyb due to previous user block and a more ergonomic alternative to sharded MySQL. Without infer support, we were able to deploy to idb, but this is with a non-trivial amount of work and required hacking infra, so, like if your product team does not have an infra background, it may not be advisable.
Last thing is that, or we noticed, as Christina mentioned, tidyb is largely compatible with MySQL, but we would not recommend deploying without sufficient preparation and benchmarks.

And with that, I’ll take additional questions, but I am also running out of time.
Hey, Andy, a couple of questions. You mentioned you ran benchmarks for correctness and, I’m assuming, scale as well. Can you tell a little bit more detail about what those benchmarks or what metrics you are testing for correctness? What? What did you test?
Another thing you mentioned used Thai CDC to move data to Snowflake. Can you share your experience with ICDC? How did that go along?
Can I go over a little bit, okay. So the first question was around. Sorry, remind me again: benchmarks, benchmarks, yes. So what benchmarks did we run? What correctness things did we check?
So the way my team does deployments, like any deployment of new code, is we run through a whole set of benchmarks against every single gRPC endpoint that’s hit by our front end.
We measure latency, throughput, and failure rates during performance tests. If we see significant performance degradation, we pause the deployment and investigate the issue. We ran the same benchmarks for TiDB, using a performance testing pod instance. For correctness, we conducted a combination of manual and automated tests, including smoke tests for our AI and general message sending and receiving. We repeated these tests until we identified any issues.
Regarding how we use TiCDC, we use it in the original way it was designed, which is to push data into Kafka. Another team manages the S3 sync component, which we use to push data into S3. We then have a separate script to pull data from S3 into Snowflake.
In terms of scale, we experienced a delay of six to eight hours when performing a backfill with TiCDC. A backfill is a single-threaded batch insert. While this delay is not ideal for analytics, it hasn’t been a showstopper for us.
If there are no further questions, you can reach us at our emails or find us at the conference. Thank you all.
